Telemetry: a big opportunity to approach scaling in the cloud – Part 1
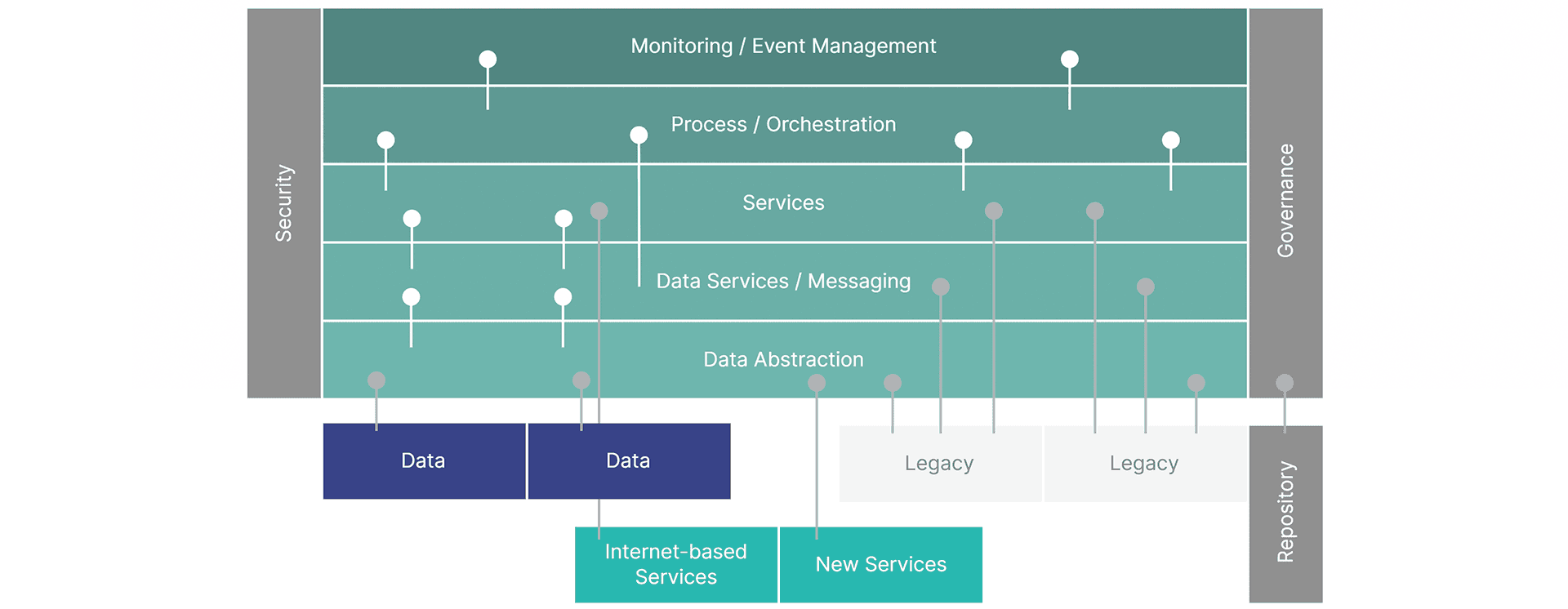
Fig. 1. SOA – Service Oriented Architecture adapted from Wikipedia

Fig. 2. Only the first request can access a Blocking Resource. Other requests are in the wait queue, while Following Processes have the capacity to serve more requests.
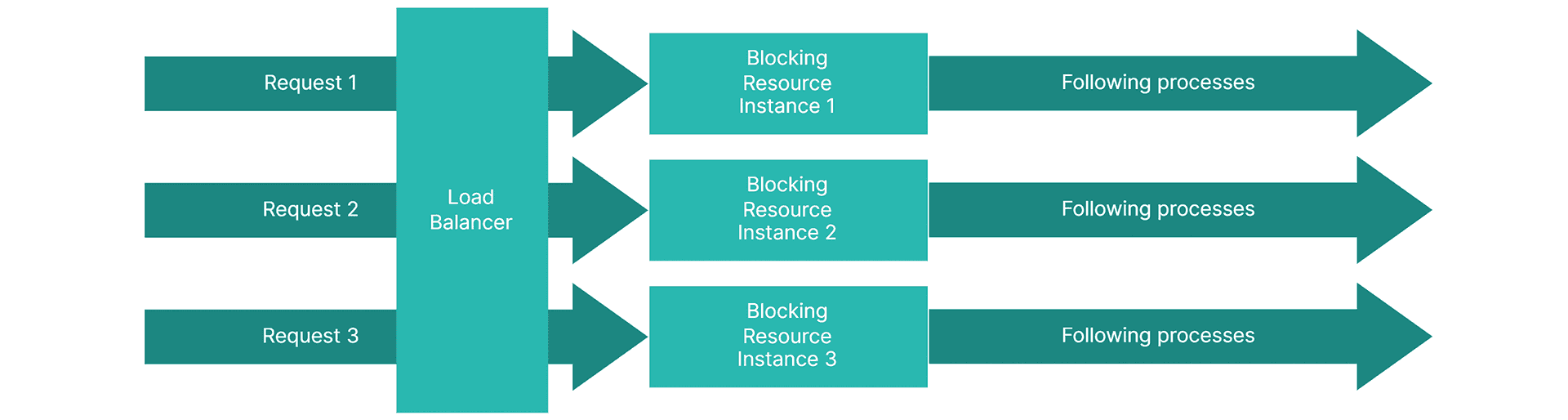
Fig. 3. Blocking Resource is scaled and each request can access its own copy
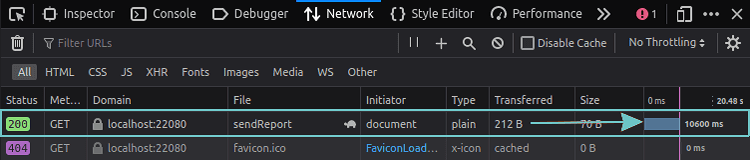
Fig. 4. All major browsers have tracing functionality. Firefox developer tools are shown.
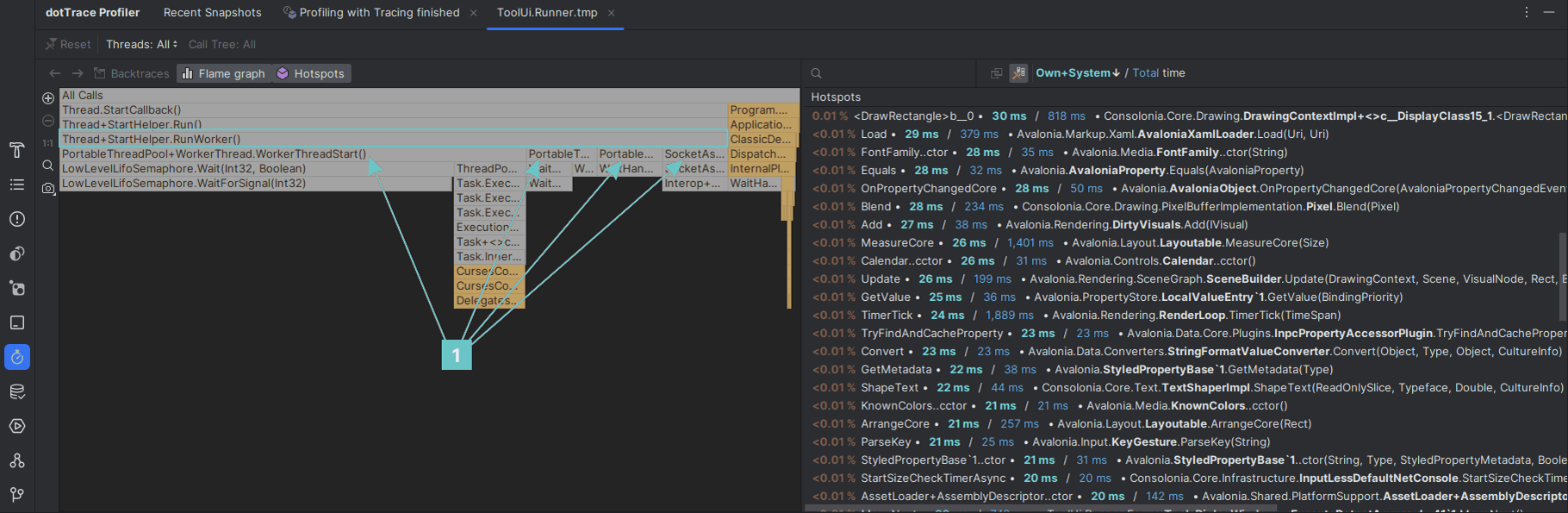
Fig. 5. JetBrains dotTrace Profiler (source: JetBrains Profiler)
Fig. 6. Sampling mode in JetBrains dotTrace